Resources&Tools
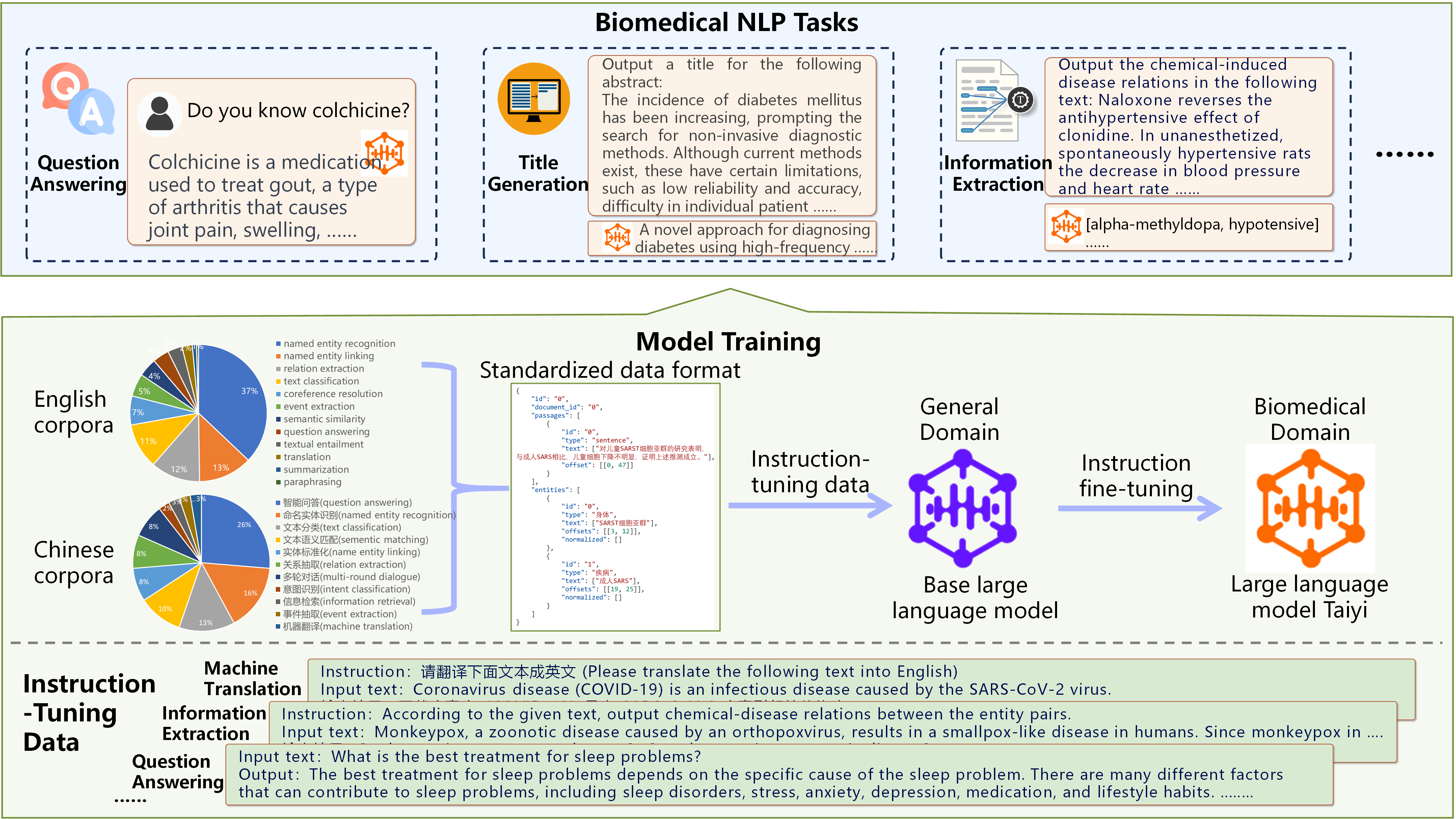 |
Taiyi (太一):A Bilingual (Chinese and English) Fine-Tuned Large Language Model for Diverse Biomedical Tasks [GitHub] To enable the general LLM to have bilingual biomedical multi-task capabilities, this project first curated a comprehensive collection of 140 existing biomedical text mining datasets, including 102 English and 38 Chinese datasets, covering over 10 biomedical task types. Then the high-quality instruction training datasets are constructed by a series of data processing, such as manual selection, data clarity, deduplication, etc, for subsequent supervised fine-tuning. In contrast to this single-stage fine-tuning, a two-stage fine-tuning strategy is proposed to optimize model performance across a diversity of tasks. Experimental results on 13 test sets demonstrate that Taiyi achieves superior performance compared to general LLMs. The case study involving additional biomedical NLP tasks further shows Taiyi's considerable potential for bilingual biomedical multi-tasking. |